在线网页爬虫工具
wwwblogs/andrew209/p/9016907.html?share_token=dea1ddd1-99b2-4493-af7d-6da798241989&tt_from=copy_link&utm_source=copy_link&utm_medium=toutiao_android&utm_campaign=client_share?= Java+selenium之WebDriver页面元素的操作(三)- 博客园 - 今日
在线网页爬虫工具怎么用
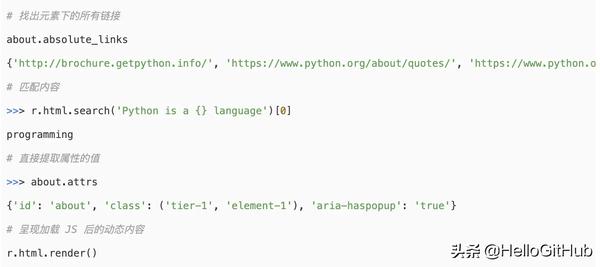
早~写爬虫的小伙伴都感受过解析 HTML 的痛苦吧?今天给你们推荐一个好帮手。requests-html 好用的 Python 解析 HTML 库。让你拥有除了常用工具 BeautifulSoup、lxml、Scrapy 的 selector 等之外另一个更好好的选择。因为它还支持 XPath、CSS 选择器、动态页面、过滤指定内容等。上手特别简单和迅速,用了它,解析 HTML 变得轻松了许多呀。

在线网页爬虫工具google插件
优秀Github开源Java项目推荐:spider-flow,一个可以用流程图的方式编写爬虫的项目,提供源码!
spider-flow是一个爬虫制作平台,提供平台源码,即,允许使用者以流程图的方式定义爬虫,是一个高度灵活可配置的爬虫平台。spider-flow平台使用Java,既能学习优秀的平台代码,又可以学习如何编写一个爬虫框架,一举两得。
spider-flow包含非常丰富的特性:
1. 支持Xpath/JsonPath/css选择器/正则提取/混搭提取
2. 支持JSON/XML/二进制格式
3. 支持多数据源、SQL select/selectInt/selectOne/insert/update/delete
4. 支持爬取JS动态渲染(或ajax)的页面
5. 支持代理
6. 支持自动保存至数据库/文件
7. 常用字符串、日期、文件、加解密等函数
8. 支持插件扩展(自定义执行器,自定义方法)
9. 任务监控,任务日志
10. 支持HTTP接口
11. 支持Cookie自动管理
12. 支持自定义函数
Github地址:github/ssssssss-team/spider-flow
还不心动吗?